两小时就能超过人类,DeepMind最新AI速通26款雅达利游戏
DeepMind的AI智能体,又来卷自己了!
注意看,这个名叫BBF的家伙,只用2个小时,就掌握了26款雅达利游戏,效率和人类相当,超越了自己一众前辈。
要知道,AI智能体通过强化学习解决问题的效果一直都不错,但最大的问题就在于这种方式效率很低,需要很长时间摸索。

而BBF带来的突破正是在效率方面。
怪不得它的全名可以叫Bigger、Better、Faster。
而且它还能只在单卡上完成训练,算力要求也降低许多。
BBF由谷歌DeepMind和蒙特利尔大学共同提出,目前数据和代码均已开源。
最高可取得人类5倍成绩
用于评价BBF游戏表现的数值,叫做IQM。
IQM是多方面游戏表现的综合得分,本文中的IQM成绩以人类为基准进行了归一化处理。
经与多个前人成果相比较,BBF在包含26款雅达利游戏的Atari 100K测试数据集中取得了最高的IQM成绩。
并且,在训练过的26款游戏中,BBF的成绩已经超过了人类。
与表现相似的Eff.Zero相比,BBF消耗的GPU时间缩短了将近一半。
而消耗GPU时间相似的SPR和SR-SPR,性能又和BBF差了一大截。

而在反复进行的测试中,BBF达到某一IQM分数的比例始终保持着较高水平。
甚至有超过总测试次数1/8的运行当中取得了5倍于人类的成绩。

即使加上其他没有训练过的雅达利游戏,BBF也能取得超过人类一半的分数IQM分数。
而如果单独看未训练的这29款游戏,BBF的得分是人类的四至五成。

以SR-SPR为基础修改
推动BBF研究的问题是,如何在样本量稀少的情况下扩展深度强化学习网络。
为了研究这一问题,DeepMind将目光聚焦在了Atari 100K基准上。
但DeepMind很快发现,单纯增大模型规模并不能提高其表现。
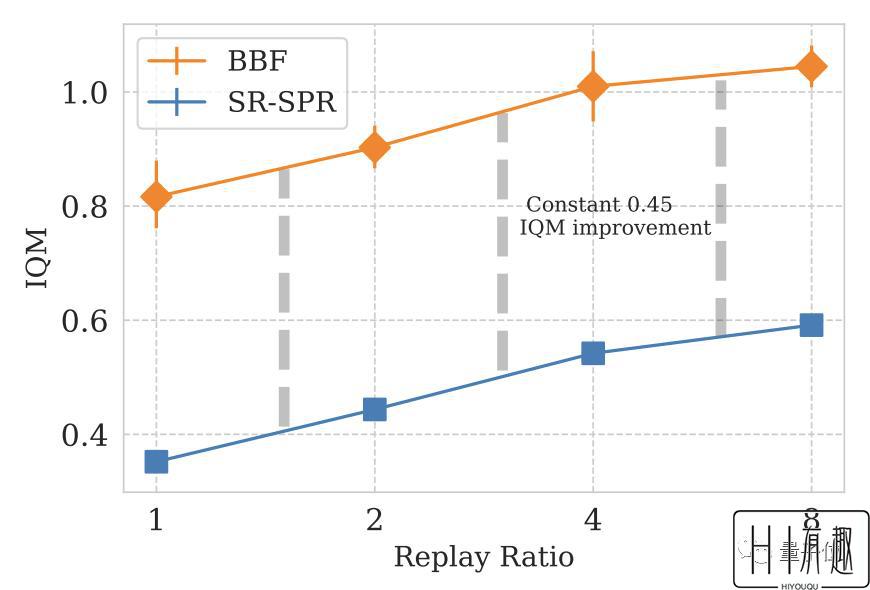
在深度学习模型的设计中,每步更新次数(Replay Ratio,RR)是一项重要参数。
具体到雅达利游戏,RR值越大,模型在游戏中取得的成绩越高。
最终,DeepMind以SR-SPR作为基础引擎,SR-SPR的RR值最高可达16。
而DeepMind经过综合考虑,选择了8作为BBF的RR值。
考虑到部分用户不愿花费RR=8的运算成本,DeepMind同时开发了RR=2版本的BBF
DeepMind对SR-SPR中的多项内容进行修改之后,采用自监管训练得到了BBF,主要包括以下几个方面:
更高的卷积层重置强度:提高卷积层重置强度可以增大面向随机目标的扰动幅度,让模型表现更好并减少损失,BBF的重置强度增加后,扰动幅度从SR-SPR的20%提高到了50%
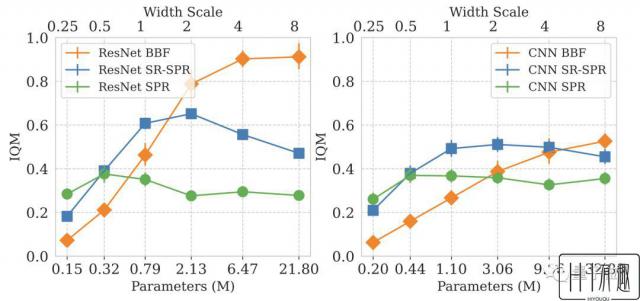
更大的网络规模:将神经网络层数从3层提高至15层,宽度也增大4倍
更新范围(n)缩小:想要提高模型的表现,需要使用非固定的n值。BBF每4万个梯度步骤重置一次,每次重置的前1万个梯度步骤中,n以指数形式从10下降至3,衰减阶段占BBF训练过程的25%
更大的衰减因子(γ):有人发现增大学习过程中的γ值可以提高模型表现,BBF的γ值从传统的0.97增至0.997
权重衰减:避免过度拟合的出现,BBF的衰减量约为0.1
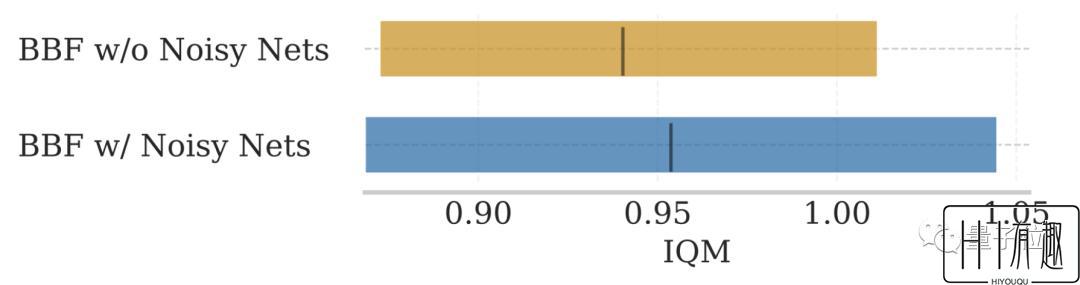
删除NoisyNet:原始SR-SPR中包含的NoisyNet不能提高模型表现
消融实验结果表明,在每步更新次数为2和8的条件下,上述因素对BBF的表现均有不同程度的影响。

其中,硬复位和更新范围的缩小影响最为显著。

而对于上面两个图中没有提到的NoisyNet,对模型表现的影响则并不显著。
论文地址:
https://arxiv.org/abs/2305.19452
GitHub项目页:
https://github.com/google-research/google-research/tree/master/bigger_better_faster
参考链接:
[1]https://the-decoder.com/deepminds-new-ai-agent-learns-26-games-in-two-hours/
[2]https://www.marktechpost.com/2023/06/12/superhuman-performance-on-the-atari-100k-benchmark-the-power-of-bbf-a-new-value-based-rl-agent-from-google-deepmind-mila-and-universite-de-montreal/
— 完 —
网友评论