我们知道,语音转换的目标是将源语音转换为目标语音,并保持内容不变。最近的任意到任意(any-to-any)语音转换方法提高了自然度和说话者相似度,但复杂性却大大增加了。这意味着训练和推理的成本变得更高,使得改进效果难以评估和建立。
问题来了,高质量的语音转换需要复杂性吗?在近日南非斯坦陵布什大学的一篇论文中,几位研究者探究了这个问题。

论文地址:https://arxiv.org/pdf/2305.18975.pdf
GitHub 地址:https://bshall.github.io/knn-vc/
研究亮点在于:他们引入了 K 最近邻语音转换(kNN-VC),一种简单而强大的任意到任意语音转换方法。在过程中不训练显式转换模型,而是简单地使用了 K 最近邻回归。
具体而言,研究者首先使用自监督语音表示模型来提取源话语和参照话语的特征序列,然后通过将源表示的每个帧替换为参照中的最近邻来转换成目标说话者,最后使用神经声码器对转换后的特征进行合成以获得转换后的语音。
从结果来看,尽管 KNN-VC 很简单,但与几个基线语音转换系统相比,它在主观和客观评估中都能媲美甚至提高了清晰度和说话者相似度。
我们来欣赏一下 KNN-VC 语音转换的效果。先来看人声转换,将 KNN-VC 应用于 LibriSpeech 数据集中未见过的源说话者和目标说话者。
我们接下来看 KNN-VC 如何运行以及与其他 jixian 方法的比较结果。
方法概览及实验结果
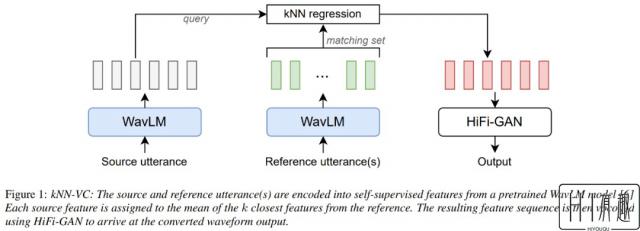
kNN-VC 的架构图如下所示,遵循了编码器 - 转换器 - 声码器结构。首先编码器提取源语音和参照语音的自监督表示,然后转换器将每个源帧映射到参照中它们的最近邻,最后声码器根据转换后的特征生成音频波形。
其中编码器采用 WavLM,转化器采用 K 最近邻回归、声码器采用 HiFiGAN。唯一需要训练的组件是声码器。
对于 WavLM 编码器,研究者只使用预训练的 WavLM-Large 模型,并在文中不对它做任何训练。对于 kNN 转换模型,kNN 是非参数,不需要任何训练。对于 HiFiGAN 声码器,采用原始 HiFiGAN 作者的 repo 对 WavLM 特征进行声码处理,成为唯一需要训练的部分。
在实验中,研究者首先将 KNN-VC 与其他基线方法进行比较,使用了最大可用目标数据(每个说话者大约 8 分钟的音频)来测试语音转换系统。
对于 KNN-VC,研究者使用所有目标数据作为匹配集。对于基线方法,他们对每个目标话语的说话者嵌入求平均。
下表 1 报告了每个模型的清晰度、自然度和说话者相似度的结果。可以看到,kNN-VC 实现了与最佳基线 FreeVC 相似的自然度和清晰度,但说话者相似度却显著提高了。这也印证了本文的论断:高质量的语音转换不需要增加复杂性。

此外,研究者想要了解有多少改进得益于在预匹配数据上训练的 HiFi-GAN,以及目标说话者数据大小对清晰度和说话者相似度的影响有多大。



网友评论